CUDA¶
Programming Massively Parallel Processors
简介
这是我学习 CUDA 的笔记。主要参考内容是《Programming Massively Parallel Processors》这本书,同时参考其他资料,将与 CUDA 有关的知识持续集成到该笔记中。笔记仅为方便复习使用,不适合初学者。
学习资源¶
最主要的参考资料应当是 NVIDIA CUDA 官方文档,里面包括了 CUDA 安装、编程指南、更高级的训练库等等整个 CUDA 生态的文档。作为 CUDA C/C++ 学习者,应当参考其中的 CUDA C++ Programming Guide。
基本知识¶
CUDA 程序的编译和运行¶
CUDA C/C++ 程序的源代码文件扩展名为 .cu。使用 NVIDIA CUDA 编译器 nvcc 能够编译这些文件。
nvcc 常用的参数如下:
| 参数 | 说明 | 示例 |
|---|---|---|
-o |
指定输出文件名 | -o hello |
-arch |
指定 GPU 架构 | -arch=sm_70 |
关于
-arch架构的详细信息,请参考:NVCC 文档。
并行计算的发展¶
- 微处理器的并行计算有两种发展轨迹:多核与多线程。
- CPU 主要走多核路线,目标是在将串行程序移动到多核处理器上时保持执行速度。它使用较为复杂的控制逻辑和缓存机制来提高单线程程序的性能。
- GPU 主要走多线程路线,目标是提高并行程序的吞吐量。GPU 的内存带宽比 CPU 高很多、能执行海量的浮点运算。
总而言之,CPU 是 low-latency(低延迟)的,GPU 是 high-throughput(高吞吐量)的。
- CUDA 是一种 heterogeneous computing platform,即异构计算平台,它允许 CPU 和 GPU 协同工作,以提高计算性能。
了解了 CPU 和 GPU 各自的方向,也就很容易理解 CUDA 为什么要做异构计算。在典型的 CUDA 程序中,Host 端的代码负责程序的主要逻辑,Device 端的代码负责海量的并行计算。
一些与历史有关的:
- 以前 GPU 专用于图形处理时,所有程序都应当适配图形应用程序接口如 OpenGL、Direct3D。并行编程人员必须将并行处理的数据对应到像素、图元等图形学概念上,才能充分利用 GPU 的并行计算能力。这种技术称为 GPGPU(General-Purpose computing on Graphics Processing Units)。
- 以前的 GPU 主要支持单精度浮点运算,然而众多科学应用要求双进度浮点运算。现在的专业 GPU 的双进度浮点运算已经接近单精度浮点运算的性能(以前只有高端 CPU 能达到),并且还支持融合运算(fused multiply-add,FMA),进一步减少误差。
CUDA 编程模型¶
一个 CUDA C/C++ 程序有 host(即 CPU)和 device(即 GPU)两部分。主机代码在 CPU 上运行,设备代码在 GPU 上运行。
主机代码和一般的 C/C++ 程序没什么区别,可以使用 OpenMP、MPI 之类的其他扩展。而在 GPU 上执行的代码称为 kernel(类比于主机上执行的函数)。CUDA 通过函数声明关键字来标记函数执行和可调用的位置。
CUDA 函数声明关键字如下表所示:
| Executed on | Callable from | |
|---|---|---|
__device__ |
Device | Device |
__global__ |
Device | Host |
__host__ |
Host | Host |
- 注意双下划线
- 不加关键字默认为
__host__ - 可以同时使用
__host__ __device__,编译器将生成该函数的两个版本。在 Host 中将调用 Host 版本,在 Device 中调用 Device 版本。
典型的核函数定义和调用方式如下:
__global__ void kernel_name(arguments) {
// kernel body
}
kernel_name<<<number_of_blocks, threads_per_block>>>(arguments);
注意到核函数的调用需要额外提供两个参数:number_of_blocks 和 threads_per_block。这两个参数决定了 kernel 的执行方式。(后面我们还会学习到其他调用参数,但这两个是必备的)。
调用 kernel 后,整个 GPU 都执行这一个 kernel 的代码,但是作为一组线程来执行。一个 kernel 的所有线程被组织成 1 个 grid,gird 又划分为 block。上面提供的这两个参数规定了划分的层级。
CUDA GPU 的硬件结构¶
CUDA GPU 的微体系结构一直在不断演进。对于不同微体系结构之间的对比,可以参考 NVIDIA GPU Architecture: from Pascal to Turing to Ampere。如果要深入了解一个具体的微体系结构,应当查阅 NVIDIA 为对应微体系结构撰写的白皮书,如 NVIDIA Turing Architecture Deep Dive Whitepaper 和 NVIDIA AMPERE GA102 GPU ARCHITECTURE。本节以实验中 2080 Ti 使用的 Turing 架构和 A100 使用的 Ampere 架构为例进行介绍。
作为 CUDA C/C++ 编程人员,我们最关心 GPU 中的两个主要部分:Global Memory 和 SM。
我们首先来看一下 Ampere 微体系结构的整体示意图,对其中的各个部分进行解读:

一个完整的 GA 100 GPU 实现包括如下部分
- 8 个GPC
- 每个 GPC 有 8 个 TPC
- 每个 TPC 有 2 个 SM
- 每个 SM 有 64 个 FP32 CUDA 核心
- 每个 SM 有 4 个第三代 Tensor 核心
- 6 个 HBM2 stacks
A100 在此基础上做了一些削减。
一个 GPU 由许多 GPC(GPU processing clusters,GPU 处理集群)、TPC(Texture Processing Clusters,纹理处理集群)和 SM(Streaming Multiprocessors,流多处理器)组成。每个 SM 由许多 CUDA 核心组成,每个 CUDA 核心都是一个 ALU(Arithmetic Logic Unit,算术逻辑单元)。
GPC、TPC 可以简单看作将 SM 组织成不同层级方便调度。事实上它们还具有 ROP(render output unit) 之类的单元,与图形处理有关,无需了解。
接下来看看 GA100 SM 的具体结构:
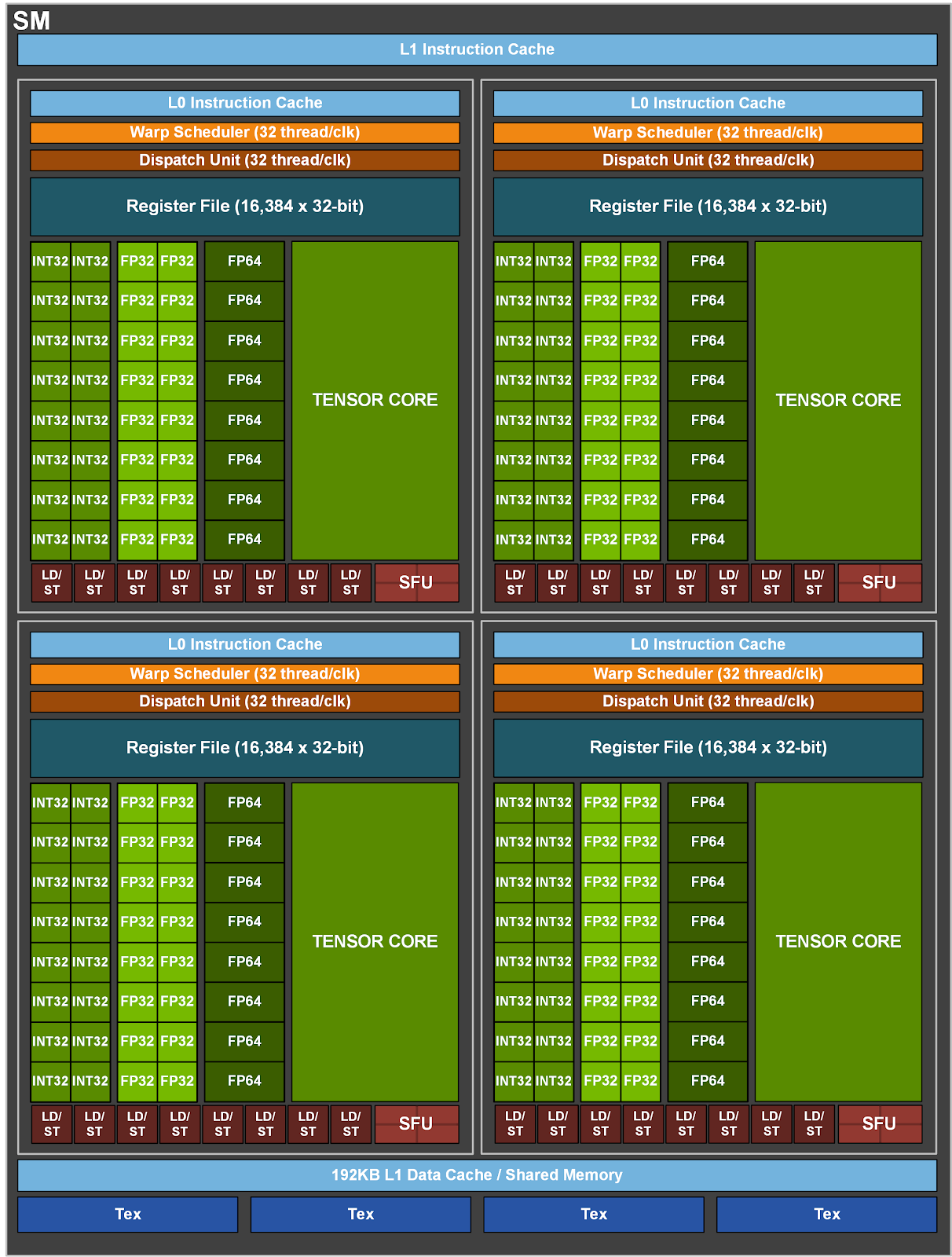
GA100 SM 的组成:
- 每个 SM 被划分为 4 个 SM partition,每个 partition 具有:
- 64 KB register file
- L0 instruction cache
- 1 个 warp scheduler
- 1 个 dispatch unit
- 一系列的数学和其他单元
- 1 个 Tensor 核心
- 4 个 partition 共享一个 128 KB 的 L1 data cache/shared memory subsystem
- 1 个 RT Core、一些纹理单元
- CUDA Datapath:CUDA 核心可以执行 FP32 或 INT 32 运算。在 Pascal 架构中,SM 要么执行 FP32 运算,要么执行 INT32 运算,而在 Turing 架构中,SM partition 将 CUDA 核心分为两个 datapath,一个执行 FP32 运算,一个执行 INT 32 运算,这样就可以同时执行 FP32 和 INT32 运算。在 Ampere 架构中,同样有两个数据通路,其中一个执行 FP32 运算,但另一个既可以执行 FP32 也可以执行 INT32(因为 FP32 的需求越来越多了)。
我们来理一理线程层级与对应的硬件资源的关系:
- 一个 thread 在一个 CUDA Core 上执行
- 一个 block 中的 thread 被分配到一个 SM 上执行
- 根据 SM 的内存资源和 block 的需求,多个 block 可以在一个 SM 上同时执行
- block 的执行顺序是不固定的,可以顺序或并发。block 之间的独立性是 CUDA 可伸缩性的关键。
- 一个 kernel 中的所有线程在一个 device 上执行
- 多个 kernel 可以在一个 device 上同时执行
虽然执行的代码相同,但具体执行的分支仍然可以不同。每个线程可以通过 threadID 来区分自己的任务。这些 ID 在 kernel 启动时固定下来。
在硬件层面上,ID 相邻的线程还会被划分成 warp 进行调度,这部分是用户无法自行定义的,其大小由硬件资源决定。warp 中的所有线程都:共享相同的代码、在一个 SM 上同时执行。多个 warp 也可以在一个 SM 上一次执行。对应到微体系结构上,由 warp scheduler(调度器) 和 dispatch unit(分派单元)来调度 warp 的执行。warp scheduler 从 SM partition 中选择 warp,然后将 warp 分派给 dispatch unit,dispatch unit 将 warp 分派给 CUDA 核心。从 Volta SM 开始,调度器具备独立的线程调度的能力,能够通过 sub-warp 的调度更好地进行优化。
通过线程调度,CUDA GPU 也具有 latency tolerance(延迟容忍)的能力。latency 指的是从主存(DRAM)中读取数据时的延迟(相较于 ALU 的执行速度来说)。由于 GPU 上同时调度大量的线程,因此可以在等待数据时执行其他线程,从而提高效率。因此,GPU 上不需要像 CPU 那样庞大的 L2 cache。
CUDA 基础编程:数据并行¶
为什么是数据并行
数据并行是并行应用程序可伸缩性的主要来源,我们通常很容易从串行程序中提取出数据并行性。任务并行性(task parallelism)则需要对算法进行重构,这是一项复杂的工作。我们会在讲解流(stream)时介绍任务并行性。
内存¶
CUDA 设备上的 Global Memory 能够被 host 访问、传输数据。除了 Global Memory,还有 Constant Memory、Shared Memory、Register、Texture Memory 等设备内存类型。
cudaMalloc()
Address of a pointer
Size
cudaFree()
Pointer
cudaMemcpy()
Destination pointer
Source pointer
Size
Direction
方向可以是 cudaMemcpyHostToDevice 或 cudaMemcpyDeviceToHost
错误处理¶
每个 CUDA API 调用都会返回一个错误码,以下是简单的写法:
cudaError_t err = cudaMalloc(&dev_a, size);
if (err != cudaSuccess) {
printf("%s in %s at line %d\n", cudaGetErrorString(err), __FILE__, __LINE__);
exit(EXIT_FAILURE);
}
还可以写成一个更完善的宏来使用:
#include <stdio.h>
#include <assert.h>
inline cudaError_t checkCuda(cudaError_t result)
{
if (result != cudaSuccess) {
fprintf(stderr, "CUDA Runtime Error: %s\n", cudaGetErrorString(result));
assert(result == cudaSuccess);
}
return result;
}
int main()
{
/*
* The macro can be wrapped around any function returning
* a value of type `cudaError_t`.
*/
checkCuda( cudaDeviceSynchronize() );
}
线程¶
每次启动内核时生成的一系列线程称为 grid。每个 grid 被组织成一系列的 block,其中的每个 block 大小相同。
一些内部变量:
- block
blockDim:block 的维度,即 block 中线程的数量。有x、y、z三个成员。blockIdx:block 的索引。有x、y、z三个成员。
- thread
threadIdx:thread 的索引。有x、y、z三个成员。
这些内部变量常常由特定的硬件寄存器存放。
每个核函数的自动变量都是线程私有的。
常用公式:
blockIdx.x * blockDim.x + threadIdx.x:线程的全局索引。ceil((float)N / block_size):block 的数量。(N + block_size - 1) / block_size:block 的数量
第 4 章 内存和数据局部性¶
上面学习的内容对性能的提升其实并不高。目前,我们程序的性能主要受限于两个方面:
- 内存访问的长延迟(几百个时钟周期)
- 主存带宽有限
虽然可以通过调度来隐藏延迟,但太多线程请求主存中的数据仍会导致拥堵。接下来我们的目标是优化程序访问内存的方式。
4.1 内存访问的性能衡量¶
我们使用浮点运算与访存次数的比值作为衡量标准,即 FLOP/Byte。这个比值也被称为算术强度(arithmetic intensity)。算术强度越高,说明程序的性能越高。
举个例子:若内存带宽为 1 TB/s,使用 FP32 进行运算时,每秒有望加载 250 G 个浮点运算数。当算数强度为 1 时,就只能达到 250GFLOPS 的性能。然而,这对 GPU 12TFLOPS 的性能来说,只有 2% 的利用率。
提高算数强度,就是要减少内存访问的次数。在上面的例子中,当算数强度达到 48,即每 48 次运算伴随一次主存访问时,我们的程序才算优化好了。
4.2 矩阵乘法¶
本节写了一个普通的矩阵乘法程序。循环中每次迭代进行了如下操作:
- 访存两次,获取两矩阵中的元素
- 一次乘法运算
- 一次加法运算
其算术强度为 1。
4.3 CUDA 内存类型¶
在上面的硬件结构中,我们介绍了几种硬件内存,回忆一下:
(待插入图片)
CUDA 提供了多种不同的存储类型帮助编程人员优化内存访问。
| Variable Declaration | Memory | Scope | Lifetime |
|---|---|---|---|
| Automatic variables other than arrays | Register | Thread | Kernel |
| Automatic arrays | Local | Thread | Kernel |
__device__ __shared__ int SharedVar |
Shared | Block | Kernel |
__device__ int GlobalVar |
Global | Grid | Application |
__device__ __constant__ int ConstantVar |
Constant | Grid | Application |
上表中,Scope 指的是能够访问变量的线程范围,Lifetime 指的是变量的生命周期。Application 生命周期的变量,在多次 kernel 调用时都存在,不需要每次初始化。
- 寄存器
寄存器延迟最低,带宽极高。访问寄存器不消耗内存带宽,减少了访存的指令(汇编层面)使得程序执行更快,也更加节能。唯一的问题是寄存器数量十分有限。
寄存器是线程私有的。
- shared memory
共享内存比寄存器慢一些,但比 global memory 快。它主要是为了 block 内的线程之间合作设计的,
- local memory
其实就是 thread local global memory
- global memory